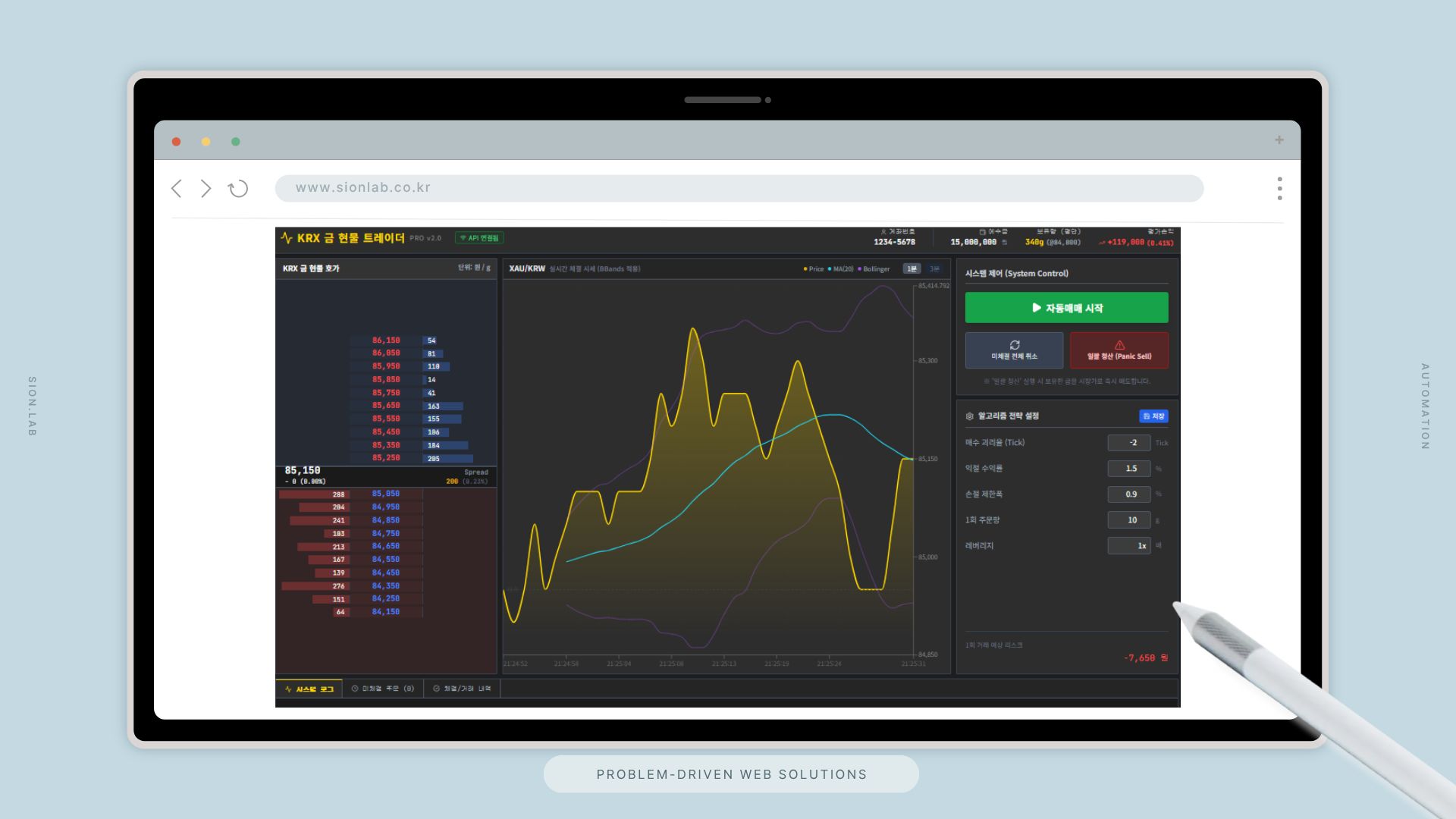
프로젝트 배경: 문제는 데이터가 아니라 시간이었습니다
고객사는 데이터가 없어서 의사결정이 느린 것이 아니었습니다. 데이터는 5개 플랫폼에 흩어져 있었고, 그것을 매일 아침 수작업으로 취합하는 데 2명이 3~4시간을 쓰고 있었습니다. 오전 10시가 지나야 전날 데이터가 완성됐고, 그제야 하루 전략 판단이 시작됐습니다.
첫 미팅에서 저희가 먼저 물은 것은 "어떤 기술을 쓸 것인가"가 아니었습니다. **"데이터가 늦어지면 어떤 결정이 늦어지는가"**였습니다. 이 질문에서 자동화 우선순위가 결정됐습니다.
설계: 단순하게 시작하는 이유
처음 제안한 아키텍처는 의도적으로 단순했습니다.
5개 소스에서 데이터를 수집하고, 형식을 통일한 뒤 저장하고, 대시보드에 반영하는 직선 구조입니다. 복잡한 시스템은 오류 원인을 찾는 데 더 많은 시간이 걸립니다. 운영 담당자가 직접 파악하고 대응할 수 있어야 진짜 자동화입니다.
# 핵심 파이프라인 구조
def run_daily_pipeline():
raw_data = collect_from_sources() # 5개 소스 수집
normalized = normalize(raw_data) # 형식 통일
save_to_db(normalized) # PostgreSQL 저장
refresh_dashboard() # Grafana 갱신
send_completion_alert() # Slack 알림가장 어려웠던 부분: 로그인이 필요한 플랫폼
5개 소스 중 2개는 로그인이 필요한 금융 플랫폼이었습니다. API가 없고 세션 기반 인증을 사용해 단순 요청으로는 데이터를 가져올 수 없었습니다.
실제로는 MFA(이중 인증) 처리, 세션 만료 시 재인증, 페이지 로딩 타임아웃 처리가 모두 추가되어야 했습니다. 이 부분에 전체 개발 기간의 40%를 투자했습니다. 데이터 수집 로직보다 안정적인 인증 유지가 훨씬 어려웠고, 더 중요했습니다.
# Selenium 기반 인증 처리
def authenticate_and_fetch(url, credentials):
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
driver.find_element(By.ID, 'username').send_keys(credentials['id'])
driver.find_element(By.ID, 'password').send_keys(credentials['pw'])
driver.find_element(By.ID, 'login-btn').click()
return extract_table_data(driver)결과와 배운 것
도입 후 한 달, 담당자에게 받은 피드백은 간결했습니다. "오전에 처음으로 전략 이야기를 할 수 있게 됐어요."
| 항목 | 도입 전 | 도입 후 |
|---|---|---|
| 데이터 취합 시간 | 매일 3~4시간 (2명) | 자동 완료 (0시간) |
| 데이터 준비 완료 시점 | 오전 10시 이후 | 오전 7시 (업무 시작 전) |
| 수작업 오류 | 월 평균 3~5건 | 0건 |
| 데이터 정확도 | 담당자 숙련도에 의존 | 99% (검증 로직 포함) |
수치만 보면 업무 시간 절감이 가장 큰 성과처럼 보입니다. 하지만 실제로 가장 큰 변화는 데이터 신뢰도가 올라가면서 경영진이 데이터를 실제 의사결정에 활용하기 시작했다는 점입니다. 데이터는 있어도 믿지 않으면 쓰지 않습니다.
자동화 자체보다 자동화된 데이터를 신뢰하게 되는 과정이 더 중요하다는 것, 이 프로젝트에서 다시 한번 확인했습니다.