기획의 시작: "데이터가 없는 게 아니에요"
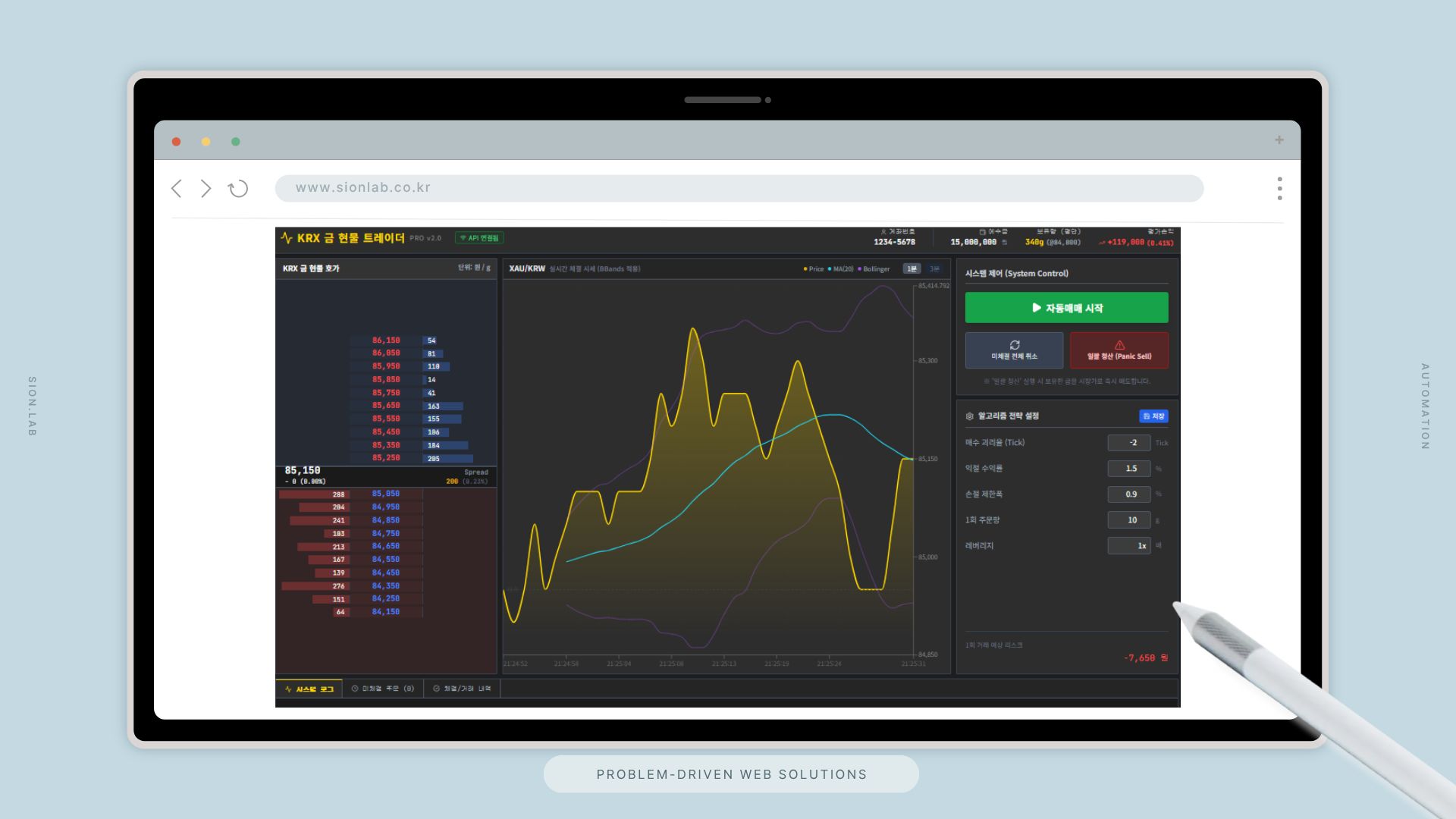
금융·회계 분야의 데이터 자동화를 기획하면서 여러 현장 담당자들의 아침 루틴을 분석했습니다. 공통 패턴이 있었습니다. 증권사 HTS, 회계 시스템, 운용사 포털, 내부 거래 시스템. 각각 로그인하고, 파일을 내려받고, 엑셀에 붙여넣는 과정이 3시간 동안 반복됩니다. 오전 10시가 지나서야 전날 포지션이 완성됩니다.
"이 작업에서 가장 아까운 게 뭔가요?"라고 물으면 답은 한결같았습니다.
"데이터가 없는 게 아니에요. 모으는 데 시간이 다 가요. 완성되면 이미 시장이 2~3시간 움직인 후예요."
전략 판단이 늦어지는 이유는 데이터 부족이 아니라 취합 구조의 부재였습니다. 이 문제를 해결하는 자동화 파이프라인을 직접 기획했습니다.
수작업 취합의 실제 흐름
소스마다 포맷이 다르고, 담당자마다 취합 방식이 달라집니다. 한 명이 빠지면 전체 취합이 늦어집니다. 이 구조에서 데이터 신뢰도를 유지하는 것은 담당자 개인의 주의력에 달려 있습니다.
자동화 파이프라인이 필요한 이유
자동화가 어렵다고 느끼는 이유 중 하나는 "각 소스가 너무 다르다"는 것입니다. 실제로는 소스 유형이 3~4가지로 수렴됩니다. 그 유형에 맞는 수집기를 만들고 연결하면 됩니다.
# 데이터 수집 파이프라인 구조
# 핵심 원칙: 소스 유형별 수집기 분리 → 공통 저장소로 통합
class DataPipeline:
def run(self, date: str):
sources = [
ApiCollector("증권사API", credentials), # REST API 소스
SeleniumCollector("운용사포털", credentials), # 로그인 필요 소스
FileWatcher("회계시스템", download_path), # 파일 다운로드 소스
DbConnector("내부DB", conn_string), # 직접 DB 연결 소스
]
for source in sources:
raw = source.fetch(date)
normalized = source.normalize(raw) # 공통 스키마로 변환
save(normalized)
notify_completion() # Slack·이메일 알림각 수집기는 독립적으로 실패합니다. 한 소스가 오류를 내도 나머지는 정상 수집됩니다. 어느 소스에서 문제가 났는지 즉시 파악할 수 있습니다.
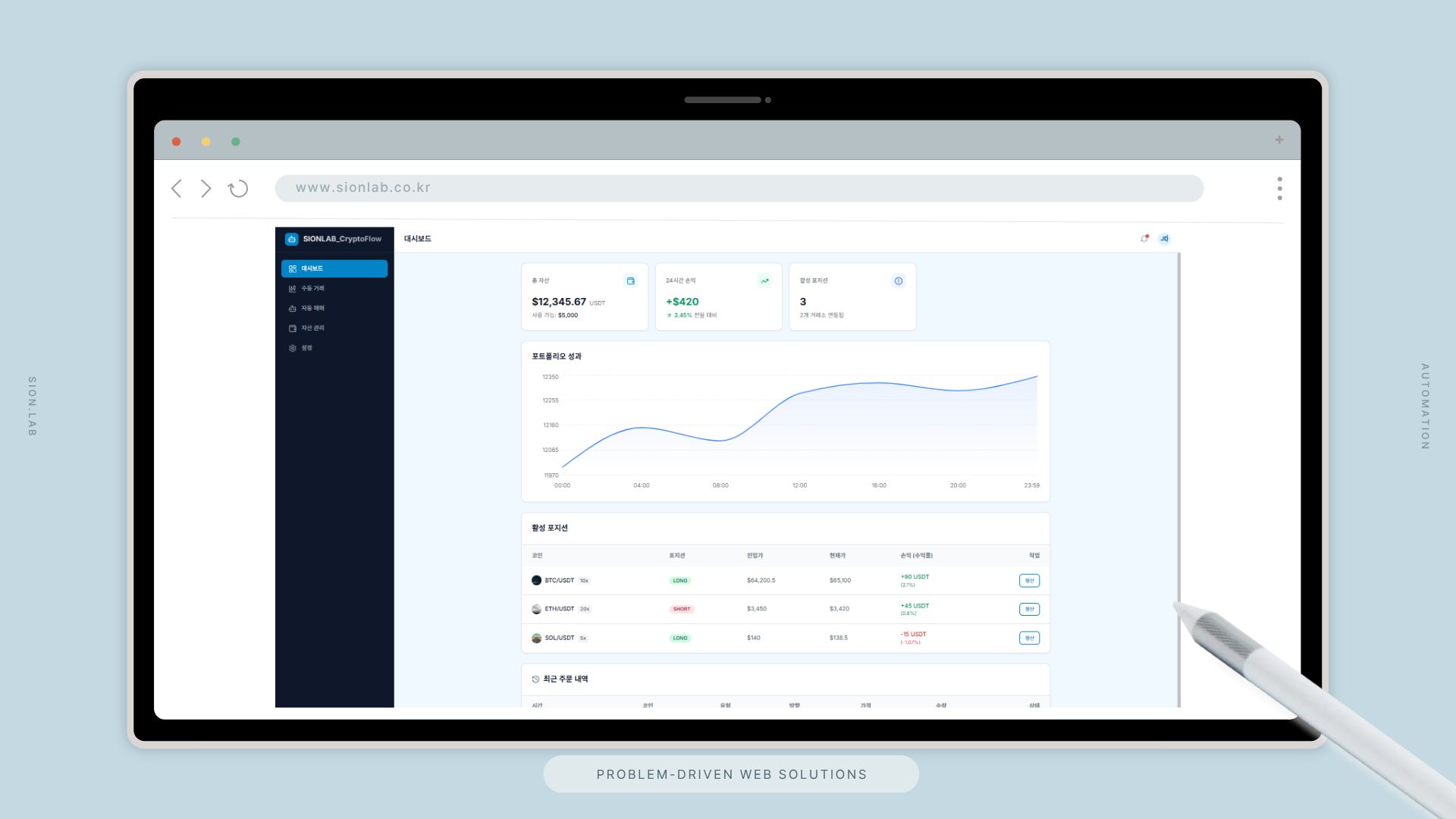
자동화된 파이프라인의 흐름
담당자가 출근하면 전날 데이터가 이미 대시보드에 올라와 있습니다. 3시간이 0분이 됩니다. 그 시간을 분석과 판단에 씁니다.
| 항목 | 수작업 취합 | 자동화 파이프라인 |
|---|---|---|
| 데이터 준비 시간 | 매일 3~4시간 | 30분 이내 (자동) |
| 오류 발생률 | 수동 입력으로 높음 | 검증 로직으로 최소화 |
| 소스 추가 대응 | 담당자 재교육 필요 | 수집기 1개 추가 |
| 장애 인지 | 결과물 누락 시 뒤늦게 발견 | 즉시 알림 |
| 담당자 부재 시 | 데이터 준비 중단 | 정상 가동 |
자동화 도입 판단 기준
데이터 취합 자동화가 맞는 상황인지 아래 기준으로 판단하세요.
- 동일한 소스에서 같은 형식의 데이터를 매일 수집하고 있다
- 취합 담당자가 특정 인원에 한정되어 있고, 부재 시 지연이 발생한다
- 수집 후 동일한 정제 작업(형식 통일, 이상값 제거)이 반복된다
- 데이터 완성 시점이 오전 업무 시간에 걸쳐 있어 의사결정이 지연된다
수집 주기가 규칙적이고 소스 형식이 안정적이라면, 자동화 ROI는 빠르게 나옵니다. 불규칙하거나 소스 구조가 자주 바뀐다면 유지 비용을 먼저 계산해야 합니다.