채용 공고, 왜 직접 보면 안 되는가
구직자든 인사 담당자든, 채용 플랫폼을 열면 같은 문제에 부딪힙니다. 공고가 너무 많습니다. 하루에도 수천 건이 올라오고, 그중 나와 관련 있는 건 극히 일부입니다. 내가 봐야 할 건 전체의 1~2%뿐인데, 그걸 찾으려면 전부 확인해야 합니다.
문제는 단순히 "시간이 오래 걸린다"가 아닙니다. 사람이 반복적으로 공고를 검토하면 판단 기준이 흔들립니다. 처음에는 꼼꼼히 보다가, 100건째쯤 되면 제목만 훑고 넘깁니다. 정작 중요한 공고를 놓치는 건 피로가 쌓인 후반부에서 발생합니다.
| 검토 구간 | 담당자 상태 | 결과 |
|---|---|---|
| 1~30건 | 집중력 높음, 꼼꼼하게 확인 | 대부분 정확히 판단 |
| 30~100건 | 피로 시작, 속도 높이려고 스킵 | 일부 공고 건너뜀 |
| 100건 이후 | 제목만 훑음, 기준 흐려짐 | 중요 공고 놓칠 확률 급증 |
이건 담당자의 역량 문제가 아닙니다. 구조적으로 사람이 감당할 수 없는 양입니다.
점수가 있으면, 전부 볼 필요가 없다
발상의 전환은 간단합니다. 모든 공고를 사람이 볼 필요가 없습니다. AI가 먼저 읽고, 각 공고에 점수를 매기면 됩니다. 점수가 높은 것만 사람이 확인하면 됩니다.
점수가 붙는 순간, 수천 건의 공고 목록은 우선순위가 있는 리스트로 바뀝니다. 상위 10%만 보면 됩니다. 나머지 90%는 시스템이 이미 걸러준 것입니다.
이 점수화가 의미 있으려면 네 가지 조건이 필요합니다.
| 조건 | 왜 필요한가 |
|---|---|
| 일관된 기준 | 사람은 피로에 따라 기준이 변하지만, AI는 1번째와 10,000번째를 같은 잣대로 봄 |
| 복합 분석 | 직무, 경력, 연봉, 위치, 기업 규모, 복지를 동시에 고려해야 정확한 점수가 나옴 |
| 실시간 처리 | 하루 수천 건이 올라오는데 다음 날 분석하면 이미 늦음 |
| 설명 가능한 근거 | "왜 이 점수인지" 이유가 있어야 담당자가 신뢰하고 사용함 |
실제로 어떻게 작동하는가
AI가 채용 공고를 점수화하는 과정은 세 단계로 나뉩니다.
1단계: 수집. 여러 채용 플랫폼의 공고를 자동으로 수집합니다. 사람이 플랫폼을 돌아다닐 필요 없이, 시스템이 주기적으로 새 공고를 가져와 중복을 제거하고 데이터를 정리합니다.
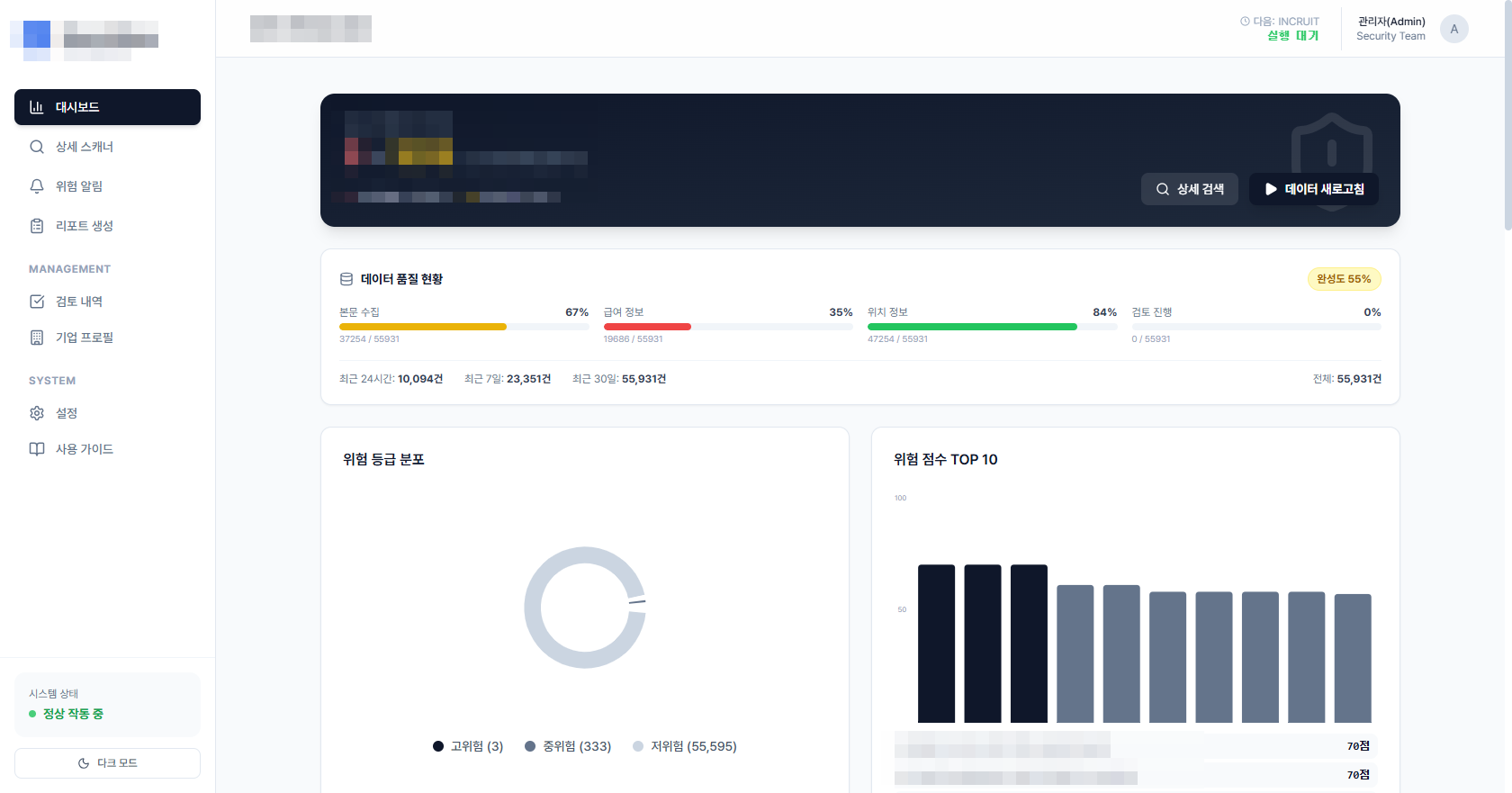
2단계: 점수화. 수집된 공고를 AI가 읽고 점수를 매깁니다. 직무 적합도, 조건의 적정성, 기업 신뢰도 등을 종합해서 하나의 점수로 만듭니다. 점수에 따라 고·중·저 등급으로 자동 분류됩니다. 이 과정에서 "왜 이 점수인지"에 대한 근거도 함께 기록됩니다.
3단계: 알림. 점수가 높은 공고가 감지되면 즉시 알림을 보냅니다. 담당자는 전체를 훑지 않고, 알림이 온 공고만 확인하면 됩니다. 주의가 필요한 공고(허위 의심, 조건 이상 등)도 별도로 경고합니다.
사람이 전부 보던 것 vs AI가 걸러준 것
| 지표 | 수작업 모니터링 | AI 점수화 |
|---|---|---|
| 확인 범위 | 눈에 보이는 일부만 | 전체 공고 자동 수집 |
| 판단 기준 | 담당자 컨디션에 따라 매번 다름 | AI 기반 일관된 점수 체계 |
| 실제 확인량 | 수백 건 직접 스크롤 | 점수 상위 공고만 확인 |
| 놓치는 공고 | 피로 후반부에서 빈번하게 발생 | 점수로 자동 필터링, 놓침 최소화 |
| 검토 이력 | 기억에 의존, 추적 불가 | 자동 기록, 언제 무엇을 봤는지 추적 |
AI 필터링이 필요한 순간
모든 채용 공고에 AI가 필요한 건 아닙니다. 하지만 아래 상황에 해당된다면, 점수화 시스템이 실질적인 차이를 만들 수 있습니다.
- 매일 확인해야 할 공고가 수십 건 이상이다
- 여러 채용 플랫폼을 동시에 모니터링해야 한다
- 공고를 놓쳐서 기회를 잃은 경험이 있다
- 검토 기준이 사람마다 달라서 일관성이 부족하다
- 어떤 공고를 언제 확인했는지 이력 관리가 안 된다
사람이 공고를 확인하는 데 쓰는 시간을, 판단하는 데 쓸 수 있게 만드는 것. AI 점수화의 핵심은 결국 그것입니다.